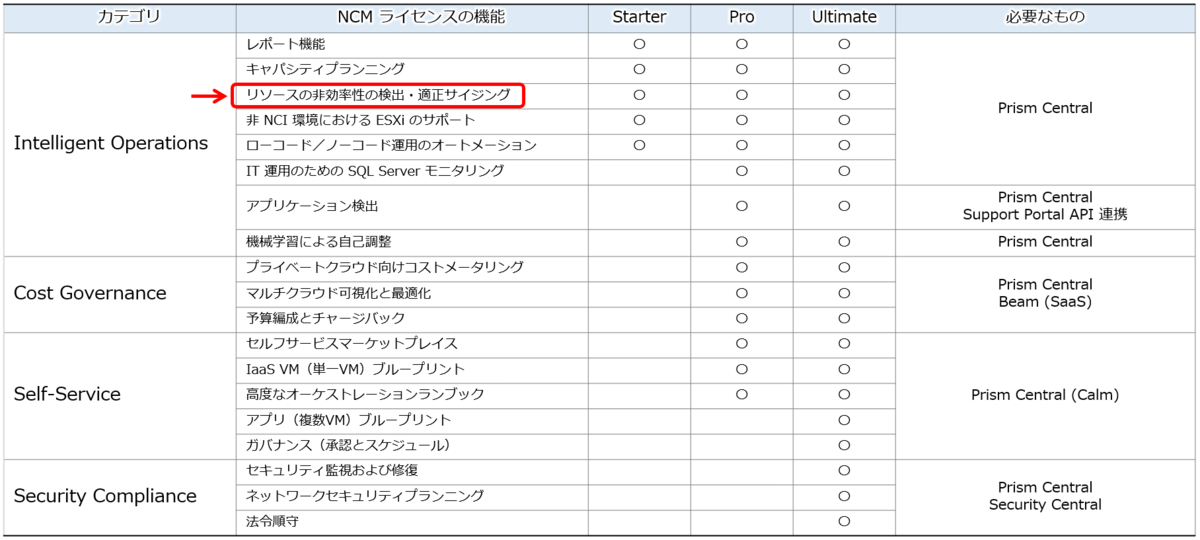
NCMの各機能の目次はこちら
- レポート機能
- キャパシティプランニング
- リソースの非効率性の検出・適正サイジング
- 非NCI環境におけるESXiのサポート
- ローコード/ノーコード運用のオートメーション
- IT運用のためのSQL Serverモニタリング
- アプリケーション検出
- 機械学習による自己調整
- プライベートクラウド向けコストメータリング
マルチクラウド可視化と最適化 - 予算編成とチャージバック
- セルフサービス(Self-Service)
- セキュリティ コンプライアンス
はじめに
前回の記事では、NCM(Nutanix Cloud Manager)の「キャパシティプランニング」について紹介しました。
今回ご紹介する機能は「リソースの非効率性の検出・適正サイジング」です。
※この記事は、Prism Centralバージョン「pc.2022.6」でのドキュメントや検証結果をもとに作成しています。その後の機能アップデートなどについては最新のドキュメントをご参照ください。
目次
- はじめに
- 目次
- 1. リソースの非効率性の検出・適正サイジングとは
- 1. VM Right Sizing(VMの適切なサイジング)
- 2. Anomaly Detection(異常検出)
- 3. Smart Alerts(スマートアラート)
- 4. Cluster Efficiency Reports(クラスター効率化レポート)
1. リソースの非効率性の検出・適正サイジングとは
こちらの機能は、Prism Centralの行動学習ツール(Behavioral Learning Tools)をもとに使用できる周辺機能のまとまりのことであると考えるとよいかと思います。
具体的には以下の4つの機能が関係します。
- VM Right Sizing(VMの適切なサイジング)
- Anomaly Detection(異常検出)
- Smart Alerts(スマートアラート)
- 特定の条件をトリガーとしたカスタムアラートを作成することができる。
- Cluster Efficiency Reports(クラスター効率化レポート)
- レポート機能の内容に、非効率なVMを含めることができる。
リソースの使用状況を定期的に見直し、効率的に使用することで、必要のないノード追加などのコストを抑えられるかもしれません。「リソースの非効率性の検出・適正サイジング」は、クラスターの規模が大きい場合やVMの台数が多くすべてを把握するのが大変な場合などには、特に役に立ちそうですね。
今回は上記の4つの機能を、すべてご紹介したいと思います。
1. VM Right Sizing(VMの適切なサイジング)
Prism Centralにて、非効率なVMを検出して表示する機能です。あらかじめ定義された4つの非効率な観点は以下の通りです。
- Bully VM(いじめっ子)
- Constrained VM(制約あり)
- 必要となるリソースが十分に割り当てられていないため、パフォーマンスに影響が出ていることが想定されるVM。CPUやメモリの使用率が90%を超えるといった評価指標が用いられる。
- Over-provisioned VM(オーバープロビジニング発生)
- 割り当てたサイズが大きすぎて不要なリソースを浪費しているVM 。CPUやメモリの使用率が少ないといった評価指標が用いられる。
- Inactive VM(保護無効)
▽これらのVMはPrism Centralのホームダッシュボードで確認することができます。

<参考>
Behavioral Learning Tools
https://portal.nutanix.com/page/documents/details?targetId=Prism-Central-Guide-vpc_2022_6:mul-behavioral-learning-pc-c.html
2. Anomaly Detection(異常検出)
VMやホスト、クラスターについて、27のメトリックが監視され、過去の傾向に基づいて今後2日間における通常状態時の行動範囲の予測が作成されます。この予測範囲(ベースライン)とは異なる値が観測された場合は、異常行動としてイベント画面に検出されます。
▽検出された異常行動のイベント。

▽ちなみに、過去の傾向から設定されているベースラインは、検出されたイベントの詳細にて確認することが可能です。以下の画像では、メモリ使用率のベースラインが60-80%の範囲であったVMを再起動したことにより、メモリの使用率が減少したため、ベースラインの下限が22%まで低下したことが分かります。

このように、Prism Centralは仮想マシンのリソース使用状況を常に監視しており、適宜ベースラインの修正をかけるような動きをします。
<参考>
Events Summary View (Prism Central)
https://portal.nutanix.com/page/documents/details?targetId=Prism-Central-Guide-vpc_2022_6:mul-alerts-event-view-pc-r.html
3. Smart Alerts(スマートアラート)
スマートアラートは、特定の条件をトリガーとしたカスタムアラートを作成することができる機能です。
▽アラートポリシーにて「User Defined」を選択します。

▽今回は例として、特定のVMのメモリ使用率が10-40%の範囲外の場合にクリティカルアラートを発行するポリシーを作成しました。(ちょっと極端ですが笑)

▽作成したカスタムポリシー

▽発行されたクリティカルアラート

▽アラートの詳細

この様に、手動で任意のトリガーを設定することで、リソースの使用状況を厳しく監視するといったこともできそうですね。
<参考>
Creating Custom Alert Policies
https://portal.nutanix.com/page/documents/details?targetId=Prism-Central-Guide-vpc_2022_6:mul-alerts-creating-user-created-policies-pc-t.html#ntask_j41_rjl_jz
4. Cluster Efficiency Reports(クラスター効率化レポート)
こちらは、第1回の記事で紹介したレポート機能において、デフォルトで準備されている「Cluster Efficiency Summary」にて確認できます。このレポートには「VM Right Sizing(VMの適切なサイジング)」の内容が含まれます。
▽Cluster Efficiency Summary

▽レポートの内容抜粋

以上「リソースの非効率性の検出・適正サイジング」の紹介でした。リソースを効率化して節約したい場合や、厳しく監視したい場合などに活用してみてはいかがでしょうか。
今回はこの辺で。
<参考資料>
Behavioral Learning Tools(pc.2022.6)
https://portal.nutanix.com/page/documents/details?targetId=Prism-Central-Guide-vpc_2022_6:mul-behavioral-learning-pc-c.html